

Big Data dit-on. Il est en effet facile d’imaginer le commerce comme l’un des acteurs majeurs du Big Data. À la fois par la surface et le nombre de ses magasins mais Big Data encore pour gérer la quantité d’utilisateurs de ses sites marchands.
Doit-on dire Big Data ou… autrement ?
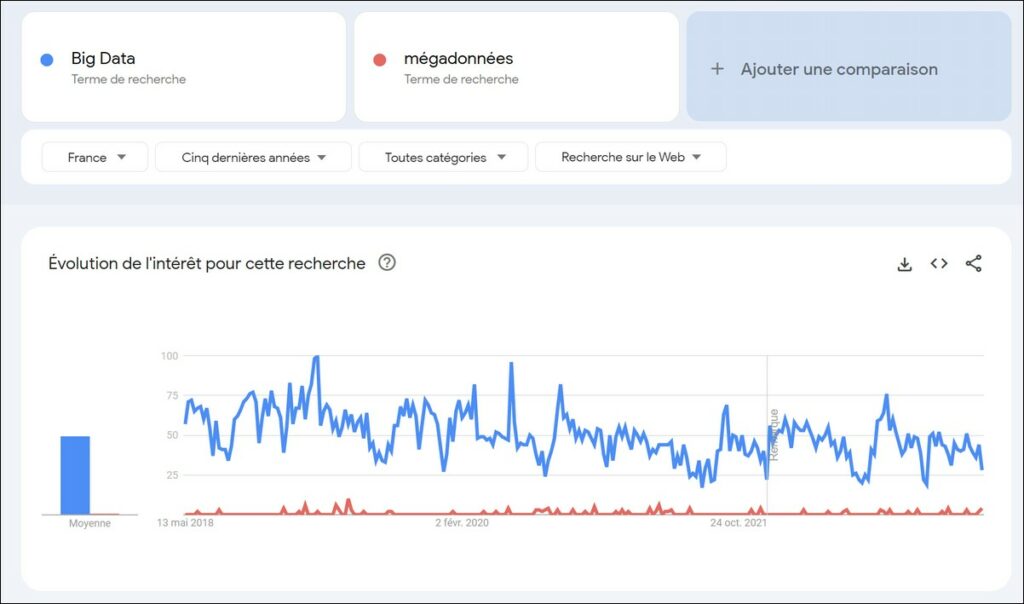
Il pourra paraître étonnant dans un article rédigé par un membre de l’Académie des sciences commerciales de se référer à une appellation étrangère. C’est que Big Data n’est pas originaire de nos vertes vallées. Et pourtant, le terme de mégadonnées serait la traduction française la plus couramment acceptée du terme « Big Data », ou encore « analyse de données » ou bien « traitement de données volumineuses ». La formulation anglo-saxonne reste de très loin la plus usitée dans les recherches sur internet[1]. cette traduction est probablement aujourd’hui dépassée, comme nous le verrons dans le cadre de cet article, compte-tenu de l’évolution fulgurante des pratiques et de la nature des données utilisées. Parallèlement, la douzaine de nouvelles fonctions créées ces dernières années constitue le meilleur indicateur de la place déterminante que la « data » et son analyse a prise au sein des entreprises y compris, bien sûr, celles de commerce.
Aux classiques « data scientist » et « data analyst » s’ajoutent désormais, entre autres, les « architect big data » et « machine learning officer ». La plupart des fonctions, méthodes et pratiques qu’elles recouvrent n’ont pas encore leurs équivalents francophones. Cela nous oblige à utiliser ici des formulations anglo-saxonnes. Outre l’analyse de l’utilisation de ces approches dans le commerce, l’un des objectifs de cet article sera ainsi de proposer des traductions pour le bon usage de la langue française, mais aussi de la compréhension des concepts que recouvrent des néologismes, pas toujours si américains que certains l’imaginent. On peut déjà s’étonner que l’analyse de données qui a longtemps été considérée comme une spécialité française grâce aux travaux dans les années 60 de Jean-Paul Benzécri, sur la classification et l’analyse factorielle et de Charles Muller, sur l’analyse textuelle[2], et les nombreuses applications logicielles qui en ont découlées ne soient pas plus reconnues.
Mais commençons déjà par déterminer les domaines d’utilisation des données de masse.
Les trois domaines d’utilisation des Big Data dans le commerce or Salon Big Data Paris 2023
Nous n’aborderons pas ici les liens entre Big Data et statistiques commerciales qui avaient déjà été évoqués dans un autre article, ni du fameux Big Data Day ou du Salon Big Data Paris 2023 si vous préférez.
Dans le commerce, et plus particulièrement dans la distribution, l’utilisation des « données de masse » est historiquement inscrite dans trois domaines d’exploitation avec des évolutions et des succès divers.
- Pour les grandes enseignes, notamment celles de e-commerce, la mercatique est le domaine que l’on associe le plus spontanément à cette démarche.
- Pourtant, il semble qu’aujourd’hui l’ensemble des échanges d’information favorisant une meilleure productivité et une optimisation des processus de gestion soit bien devenu le terrain privilégié d’application. Ce choix s’observe principalement au niveau des investissements et de la gestion des ressources humaines.
- Le troisième domaine, lié à l’utilisation des données à des fins de réflexion stratégique, tant en termes de diagnostic que de prise de décision, apparaît moins courant dans la pratique quotidienne des entreprises du commerce même s’il reste au cœur de nombreux débats.
Force est en conséquence de séparer le poids médiatique de ces différents domaines tels qu’il peut s’observer aujourd’hui entre la production des livres blancs ou webinaires de nombreuses « jeunes pousses[3] » et les allocations budgétaires des entreprises.
La chaîne d’approvisionnement : un thème de prédilection pour les données de masse (Big Data)
Le focus mis sur l’organisation interne et l’optimisation des processus dans les enseignes notamment physiques est la conséquence de deux pratiques historiques associées à une certaine vision de la technologie.
- La première de ces pratiques est liée à la déjà longue expérience du stockage des données de caisse alors même que les technologies de l’époque n’en permettaient qu’une utilisation limitée pour des analyses opérationnelles ou stratégiques. Ces données étaient perçues comme capitales dans les échanges avec les fournisseurs tant pour déterminer les conditions commerciales que pour en mesurer les réalités. Elles étaient avant tout conçues comme la réponse des enseignes aux données des panels. Ces derniers représentant la seule source d’information sur les comportements d’achat des consommateurs[4]. A la même époque apparaissaient dans les techniques de marchandisage, les premiers logiciels, Spaceman chez Nielsen et Apollo chez Vepro Conseil, tous deux ramenés des Etats-Unis. Si ces logiciels dans un premier temps pouvaient se contenter des données de panel disponibles au niveau national, il devint vite évident que les informations spécifiques de chaque point de vente constituaient une approche plus réaliste et, de fait, plus efficace. Si cette évolution vers une quantification croissante des analyses a eu un intérêt réel et a prouvé son efficience économique, elle ne doit pas faire oublier qu’elle a aussi mis au second plan certains aspects plus qualitatifs. Rappelons ici la définition du marchandisage d’Alain Wellhoff : « ensemble des méthodes et des techniques concourant à donner au produit un rôle actif de vente dans sa présentation et son environnement pour optimiser sa rentabilité[5] ».
- La deuxième pratique est représentée par la réduction des ruptures de présence des produits en linéaire fondée sur le suivi détaillé des stocks à toutes les étapes de la chaîne logistique, d’une part, et celui des ventes, d’autre part. Perçues comme une perte de revenus évidente, mais surtout comme une source de perte potentielle de clientèle, la réduction des ruptures a toujours été l’une des priorités des stratégies de gestion du point de vente. Malgré les efforts réalisés, et les budgets dépensés, les regards portés par les consommateurs restent durs[6] : 91% des français déclarent avoir connu des ruptures de stocks en rayon, 48% s’en disant déçus et 19% en colère. Pour 74% des personnes interrogées, cette réalité n’est pas plus acceptable aujourd’hui qu’hier. 40% sont alors prêts à changer de magasin, soit un chiffre relativement identique à celui mesuré depuis les années 90.
Les lois applicables dans le domaine du Big Data
C’est ici qu’il faut rappeler une certaine vision de la technologie. La technologie, qui a porté ces pratiques, peut être résumée en quelques « lois » :
- loi de Moore sur la puissance de calcul,
- loi de Moore dérivée et appliquée aux capacités de stockage mémoire,
- loi de Gilder sur la bande passante,
- loi de Metcalfe sur la puissance des réseaux.
Toutes ces lois semblaient justifier d’une absence de limites dans les capacités de stockage de la donnée, dans la puissance de calcul et la vitesse de traitement. Elles semblaient donc promettre un futur où les ruptures n’existeraient plus et où le consommateur trouverait à tout moment le produit convoité. Aujourd’hui, on ne peut que constater l’écart entre le facteur d’un milliard qu’ont connu les performances de traitement et la baisse réelle des taux de ruptures. Plus interpellant est de comparer les performances des 10 à 15% de commerces soumis à des programmes de gestion de la donnée, soit le plus souvent les commerces sous enseigne, et celles des 85 à 90% de commerçants indépendants et isolés, pour qui cette gestion reste inconnue.
Big Data et mercatique : une voie royale issue de la vente à distance
Revenons alors à l’utilisation des données de masse dans les stratégies mercatiques. Elles ont, bien sûr, profitées des mêmes évolutions technologiques. Et pour beaucoup d’entre-elles, elles ont aussi constitué une course à la quantité. Si l’on ne devait donner qu’une justification à l’utilisation de l’expression big data ce serait peut-être simplement en rappel à la célèbre sentence « big is beautiful » qui connaît actuellement un net retour en grâce[7]. Si les deux pratiques historiques et la vision technologique précédemment évoquées ont aussi largement irrigué les choix opérationnels dans le domaine mercatique, s’y est ajoutée une vision de la relation idéale fondée sur le « un à un[8] » ou le « face à face », soit une relation totalement individualisée. Cette approche n’est pas issue de la distribution physique, mais des acteurs de la vente à distance.
Ainsi, dès 1987[9], deux des plus éminents spécialistes de cette profession, Stan Rapp et Thomas L. Collins, publiaient leur théorie du « maxi-marketing », orienté sur la « dé-massification » des marchés, le déclin de la fidélité aux marques et aux produits en partie due à la prolifération des nouveautés et des promotions, le développement de l’économie de services, la multiplication des canaux de distribution et des moyens de paiement qui liés aux transformations des cellules familiales et au développement des bases de données favorisait l’apparition d’un nouveau paradigme commercial. Dans leurs écrits, un mot revenait en boucle : optimiser. Optimiser le ciblage, les médias, la sensibilisation et l’activation, la synergie et la continuité des processus. Enfin, et surtout, optimiser le rapport coût-efficacité, que nous appelons plus volontiers aujourd’hui ROAS[10], soit le chiffre d’affaires généré par euro investi. Autant de concepts que l’on retrouve désormais dans toutes les stratégies mercatiques ou e-mercatiques sous d’autres dénominations donnant ainsi les habits neufs de la disruption à des principes déjà anciens.
Cette logique de la personnalisation à l’extrême des produits s’observe aujourd’hui chez L’Occitane, Carte Noire, Marvel ou encore Zegna. Mais elle s’exprime encore mieux dans la personnalisation des messages rendue possible par les vitesses de calcul et de transmission. Toutefois, développer cette stratégie nécessite un accroissement constant des informations disponibles pour rendre toujours la personnalisation plus contextuelle et immédiate.
Pourquoi il ne faut pas traduire Big Data par mégadonnées
Les bases de données sont en conséquence toujours plus grosses comme le souligne la dénomination des octets : Méga, Giga, Téra, Peta, Exa…. Les mégadonnées sont ainsi devenues des exadonnées, rendant, de fait, caduque, la traduction de « big data ». Mais problème ! Les deux tiers des français cherchent à limiter leur partage de données, méfiants face aux utilisations et détournements potentiels. Toutes ces informations que certains qualifient d’infobésité suffisent-elles pourtant à répondre efficacement aux attentes des clients ? Rien n’est moins sûr. À présent, 44 % des consommateurs déclarent être susceptibles d’aller faire leurs achats ailleurs s’ils n’obtiennent pas l’expérience individualisée à laquelle ils ont été habitués !
Les critères majeurs de construction d’une base de données : quand les consommateurs s’opposent aux experts
Les spécialistes citent souvent cinq informations qui constituent le socle minimal de toute base de données. Volontairement, nous changerons l’ordre qu’ils utilisent généralement :
- En priorité, l’âge. Pourtant une étude récente menée pour le compte d’Adobe en 2022 auprès de plus de 2 000 français, si elle confirme le besoin de distinction, précise dans le même temps que 57% d’entre eux ne voient pas leur âge comme un critère pertinent de différenciation et que 72% ne se reconnaissent pas dans une segmentation générationnelle.
- Deuxième information, le genre, dont on connaît pourtant la difficulté croissante de définition et surtout la sensibilité exacerbée de nombre de personnes sur toute forme de catégorisation hâtive.
- Le cinquième critère retenu par les experts concerne les niveaux de satisfaction clients. Si cette variable semble relativement facile à mesurer elle ne permet le plus souvent que de qualifier les points de friction répétitifs dans une relation client. Elle n’est en rien prédictive d’un comportement futur. Un simple accroc pouvant ruiner des années d’effort et de relations harmonieuses.
- Plus compliqué encore est le quatrième critère de qualification retenu, à savoir déterminer et suivre dans le temps les centres d’intérêt des clients comme autant de critères de ciblage. Plus facile à dire qu’à faire surtout si l’on vise à l’exhaustivité et à la précision. Si la disparition annoncée des « cookies tiers » qui permettaient de collecter de la donnée risque de réduire fortement l’intérêt de nombreux sites internet et de leurs assistants virtuels associés[11], elle donne en revanche un réel avantage aux applications. Près de 79% des directions mercatiques sont inquiètes de la disparition de ces cookies, qu’elles jugent indispensables pour connaître leurs clients et personnaliser la relation.
- Ne reste alors que les données issues des achats et des parcours clients pour définir, à minima, des segments de clientèle (« personna » étant désormais le terme utilisé par les « connaisseurs »), au mieux, une réelle personnalisation. Ce troisième critère retenu par les professionnels est ici encore largement porté par la technologie qui vient au secours de tout gestionnaire de base de données. Mais ici la main est partagée avec les gestionnaires de moyens de paiement qui disposent d’une vision plus transversale et diversifiée des parcours clients.
Vers une vision plus stratégique de la donnée ? Grâce au Big Data
Trois approches semblent actuellement se dégager dans la collecte et l’analyse des données clients.
- La plus apparente est le maintien d’une course à la quantité appuyée par la puissance technologique. Aujourd’hui l’intelligence artificielle statistique[12] sous diverses formes, demain les applications courantes issues de la « chaîne de blocs » et des jetons non fongibles (NFT). Assistant à plusieurs séminaires sur les données et leur gestion ces derniers mois, j’ai ainsi pu constater que l’une des questions qui revenait le plus souvent était de savoir si l’on devait travailler à partir d’un « lac de données » ou d’un « maillage de données », ou encore, si les leaders (chefs de file) utilisaient plus de solutions intégrées ou plus d’« association des meilleures solutions par fonction »[13] ! La question sous-jacente étant alors « est-ce que je fais les choses comme il faut ? » plutôt que « est-ce que je fais les choses qu’il faut ? ». Soit un accent mis sur l’opérationnel et la justification plutôt que sur le stratégique et la prise de risque.
- Deux autres voies semblent se dessiner, moins orientées sur la masse des données que sur l’approche conceptuelle de l’analyse. Ainsi, Amélie Poisson, directrice générale adjointe de La Redoute en charge du commerce et du marketing, déclare privilégier aujourd’hui l’interrogation directe des clients sur leurs attentes et centres d’intérêt plutôt que la création de routines et d’analyses prédictives complexes. La taille de la base de données, la disposition d’un historique complet de la relation clients et l’utilisation d’algorithmes sophistiqués n’apparaissent plus la panacée. Seule une relation directe avec le client, via un échange d’informations utiles et contextualisées permet de recueillir les informations nécessaires. Fin des assistants virtuels, eux-mêmes assistés par Chat GPT ? Retours aux bons vieux SMS et centres de réception d’appel ? Probablement pas, mais plus sûrement un mélange de données de suivi pour la quantification et de données déclaratives pour la qualification, appuyé par une intelligence artificielle conceptuelle plutôt que statistique. Cette approche prend en compte d’autres lois technologiques qui montrent que contrairement aux idées reçues la taille devient rapidement un frein à l’efficacité. Loi de Wirth / Reiser sur le ralentissement des programmes et surtout Loi de Dunbar qui indique une limitation à la loi de Metcalfe précédemment évoquée : l’efficacité d’un réseau tient au nombre de liens créés entre chaque membre, mais pour que ces liens soient réels et forts il faut que le nombre d’acteurs reste limité[14]. Une image quotidienne de ce principe est donnée par les réseaux sociaux avec le passage des grands groupes indifférenciés (Facebook) aux groupes d’appartenance multiples (WhatsApp).
- Enfin, depuis deux à trois ans on observe le développement rapide de partages de données entre les distributeurs, les régies et les annonceurs au sein d’espaces de travail mutualisés et protégés[15]. Si pour reprendre la formulation de Pauline Boedels, directrice générale adjointe de l’Agence 79 (Havas) « on en est encore au stade de l’effervescence », l’année 2023 devrait voir l’émergence d’un réel marché pour les éditeurs de plateformes. Cette dernière évolution apparaît comme une rupture majeure. Jusqu’à présent la logique dominante favorisait l’utilisation de données internalisées. Soit un « renfermement sur soi » des entreprises, où les investissements technologiques et la gestion des talents dans les politiques RH étaient les meilleurs garants de l’efficacité concurrentielle. Désormais c’est par le partage de l’information entre acteurs d’une même chaîne de valeur, voir potentiellement entre concurrents, que l’on cherche à optimiser la connaissance des clients, de leurs parcours d’achat et parallèlement le suivi des process de distribution.
De la technologie à l’humain ?
Il semble ainsi que l’on assiste à une double prise de conscience. D’une part, celle de la limitation de la quantité des données collectables, et d’autre part, de la difficulté de maitriser toutes les interprétations nécessaires. L’émergence actuelle de la fonction de « prompt engineer » en est l’un des signaux faibles.
Les acteurs vont-ils préférer mettre en commun leurs connaissances spécifiques au bénéfice d’une meilleure efficacité ? Si cette approche semble aujourd’hui limitée au domaine de la publicité et du média commerce, elle pourrait se diffuser à tous les secteurs des entreprises et tous les types d’acteurs.
Faudrait-il encore que les entreprises se focalisent moins sur l’optimisation de leurs processus internes. A l’inverse, peut-on imaginer des entreprises en réseau, cherchant l’innovation dans le partage des données, mais aussi dans le partage des intelligences humaines, privilégiés à l’adoption de la dernière technologie ? Comme pour les problèmes environnementaux, il semble bien que nous soyons à l’heure des choix.
Définition de Big Data selon ChatGPT 4
Le terme « Big Data » fait référence à de grandes quantités de données qui sont générées, collectées et stockées à une échelle massive. Le concept de Big Data repose sur trois caractéristiques principales, connues sous le nom des « 3 V » :
- Volume : Il fait référence à la quantité de données générées. Avec les avancées technologiques, nous sommes capables de collecter et de stocker d’énormes volumes de données provenant de différentes sources, telles que les médias sociaux, les appareils connectés, les transactions commerciales, etc.
- Vélocité : Cela se rapporte à la vitesse à laquelle les données sont générées, collectées et traitées. Dans un monde de plus en plus connecté, les données sont générées en temps réel à un rythme fulgurant. Le Big Data nécessite des outils et des technologies capables de traiter ces données rapidement pour en extraire des informations pertinentes.
- Variété : Cela se réfère à la diversité des types de données générées. Les données peuvent être structurées (telles que les bases de données traditionnelles), semi-structurées (comme les fichiers XML) ou non structurées (comme les e-mails, les vidéos, les images, les tweets, etc.). Le Big Data englobe ces différentes formes de données et nécessite des méthodes d’analyse adaptées à chaque type.
En résumé, le Big Data peut être défini comme l’ensemble des données massives, complexes et en constante évolution qui nécessitent des technologies et des méthodes spécifiques pour être collectées, stockées, traitées et analysées. Ces données peuvent être exploitées pour obtenir des informations précieuses, des tendances, des modèles et des connaissances qui peuvent aider les entreprises, les organisations et les chercheurs à prendre des décisions plus éclairées.
Image d’illustration par Tumisu de Pixabay
[1] Le terme « big data » est désormais 48 fois plus utilisé que le terme « mégadonnées » lorsque l’on effectue la recherche sur Google Trends sur les cinq dernières années. Même chez nos amis québécois dont nous connaissons la sensibilité au respect de la francophonie, le terme anglais apparaît définitivement adopté, avec moins de 2% d’utilisation de « données de masse » ou de « mégadonnées » !
[2] Valérie Beaudouin – Retour aux origines de la statistique textuelle – JADT 2016.
[3] i.e. start-up en langage plus courant.
[4] voir les travaux de Lazer (1963), Wind and Greeen (1974), et pour la France, Le Maire, Evrard et Douglas (1973)
[5] Qu’est-ce que le merchandising – J.E. Masson et A. Wellhoff – Dunod Entreprise – 1985
[6] Étude OpinionWay / SES-imagotag « Les Français et la rupture de produits en rayons » Mars 2023
[7] Big Is Beautiful: Debunking the Myth of Small Business – 30 mars 2018 – Édition en anglais de Robert Atkinson – Michael Lind
[8] Traduction littérale en français de marketing one to one.
[9] MaxiMarketing : The Nex Direction in Advertising, Promotion and Marketing Strategy, Stan Rapp et Thomas L. Collins, McGraw-Hill 1987
[10] ROAS : Return on Ad Spend
[11] Assistants virtuels = chatbots
[12] Pour reprendre la formulation de Luc Julia.
[13] “Best of breed” dans le langage courant.
[14] On pourrait aussi citer ici la théorie de l’acteur-réseau développée à partir des années 80 par Michel Callon, Bruno Latour et Madeleine Akrich – Centre de Sociologie de l’Innovation – Mines Paris Tech.
[15] Data Clean Room.
Plutôt de parler de big Data, penchez vous sur les small ou smart data : les données opérationnelles réellement disponibles.
85% des projets Big Data n’arrivent jamais au stade opérationnel (Gartner).
Et on ne parle que de cela car les outils capables de tirer de la valeur de petits jeux de données sont très rares.
Il est temps de changer de paradigme ! La Big Data est morte car inutile dans la très grande majorité des cas.
Venez voir ce que propose une pépite française de l’IA : MyDataModels.
Je suis tout à fait d’accord avec vous sur le fait que l’on peut s’interroger sur la réalité des stratégies « big data ». Vous insistez sur le faible nombre d’implémentations réelles mais l’on pourrait dire la même chose des fusions-acquisitions, des mises en place de CRM, etc., sans que cela interroge grand monde. Pour ma part, j’ai préféré présenter l’écart entre puissance technologique et investissements, d’une part, et performance, d’autre part.
Je ne pense pas qu’il s’agisse d’opposer « big » et « small », mais plutôt volume de données et outils statistiques à données maîtrisées et outils conceptuels. Je reprends ici volontiers l’opposition que pose Luc Julia entre IA statistique et IA conceptuelle qui me paraît à la fois éclairante et opérationnelle. Quand à la notion de « smart », je reprends aussi volontiers la formule de Michel Sudarskis, délégué général de l’Association Internationale du Développement Urbain quand il évoque le concept de smart city » ce ne sont pas les Villes qui sont intelligentes, mais les hommes. » Selon moi, la même logique s’applique aux données.
Il est sûrement nécessaire de changer de paradigme, mais une analyse des jeux d’acteurs en place montre que le « suivisme » et l’imitation ont probablement une longue vie assurée. Relire ici les travaux fondateurs de Gabriel Tarde.
Etant moi-même confronté quotidiennement aux problèmes, je suis à votre entière disposition pour étudier les offres de MyDataModels.